
00:00:00
Transformer学习笔记
1、Vision Transformer(ViT)
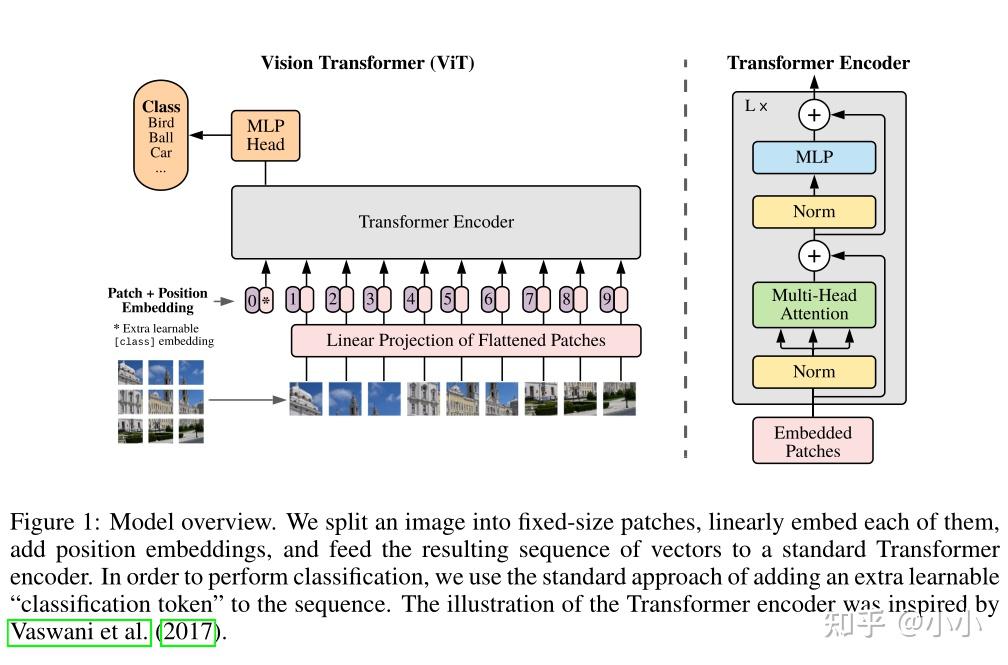
1.1、pytorch实现
1.1.1、导入必要的包
python
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange需要安装einops
pip install einops
1.1.2、编写代码函数
1.1.2.1、pair函数
python
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# print(pair(4)) # (4, 4)作用是:判断t是否是元组,如果是,直接返回t;如果不是,则将t复制为元组(t, t)再返回。 用来处理当给出的图像尺寸或块尺寸是int类型(如224)时,直接返回为同值元组(如(224, 224))。
1.1.2.2、PreNorm函数
python
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)PreNorn对应框图中最下面的黄色的Norm层。其参数dim是维度,而fn则是预先要进行的处理函数,是以下的Attention、FeedForward之一。
1.1.2.3、FeedForward函数
python
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)FeedForward层由线性层,配合激活函数GELU和Dropout实现,对应框图中蓝色的MLP。参数dim和hidden_dim分别是输入输出的维度和中间层的维度,dropour则是dropout操作的概率参数p。
1.1.2.4、Attention函数
python
class Attention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout),
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim=-1) # (b, n(65), dim*3) ---> 3 * (b, n, dim)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv) # q, k, v (b, h, n, dim_head(64))
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)Attention,Transformer中的核心部件,对应框图中的绿色的Multi-Head Attention。参数heads是多头自注意力的头的数目,dim_head是每个头的维度。
本层的对应公式就是经典的Tansformer的计算公式:
具体分析一下这个注意力函数,假设x.shape = (32, 10, 128),即输入(batch_size=32, sequence_length=10, dim=128):
1、经过b, n, _, h = *x.shape, self.heads后
b = 32:批次大小(batch size)。n = 10:序列长度(sequence length)。_ = 128:输入特征的维度(dim),这里用_表示因为后续不需要直接使用这个值。h = 8:注意力头的数量(self.heads)。
2、之后经过线性层qkv = self.to_qkv(x).chunk(3, dim=-1) 映射到Q、K、V,
self.to_qkv(x)通过一个线性层将x映射为查询(Q)、键(K)、值(V)三个部分。- 输入
x的形状是(32, 10, 128),self.to_qkv的输出形状为(32, 10, 64*8*3) - 然后使用
chunk(3, dim=-1)将这个张量分割成三个形状为(32, 10, 64*8)的张量,即q,k,v。
3、重排Q、K、V,q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv),
q, k, v 的初始形状为 (32, 10, 512)。
rearrange(t, 'b n (h d) -> b h n d', h=h)将每个张量从(32, 10, 512)重新排列为(32, 8, 10, 64),其中,h = 8是头的数量,d = 64是每个头的维度。- 因此,经过
rearrange后,q,k,v的形状都是(32, 8, 10, 64)。
4、计算点积注意力dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale,
- 使用
einsum计算q和k的点积,结果是dots,形状为(32, 8, 10, 10): - 其中,
b=32:批次大小,h=8:注意力头的数量,i=10:查询序列的长度,j=10:键序列的长度,self.scale缩放因子是1 / sqrt(16),用于避免点积结果过大,对应公式的 - 这个
dots张量表示每个查询位置和每个键位置之间的相似性。
5、通过Softmax进行归一化,得到注意力权重,输出形状仍为(32, 8, 10, 10)
6、使用注意力权重加权 V,out = einsum('b h i j, b h j d -> b h i d', attn, v),
- 使用
einsum将attn与v相乘,计算加权求和,得到输出out。 - 结果的形状是
(32, 8, 10, 64),表示每个头的加权输出。
7、重新排列,out = rearrange(out, 'b h n d -> b n (h d)'),
- 将
out从形状(32, 8, 10, 64)重排回(32, 10, 64*8): h=8是头的数量,d=16是每个头的维度,(h d)就是64*8,因此将所有头的输出拼接在一起
8、进行线性投影,return self.to_out(out),
- 输入形状是
(32, 10, 128),输出的形状仍然是(32, 10, 128)。
1.1.2.5、Transformer Block
python
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x定义好几个层之后,我们就可以构建整个Transformer Block了,即对应框图中的整个右半部分Transformer Encoder。有了前面的铺垫,整个Block的实现看起来非常简洁。
参数depth是每个Transformer Block重复的次数,其他参数与上面各个层的介绍相同。
1.1.3、综合
1.1.3.1、完整的类定义
python
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool='cls', channels=3, dim_head=64, dropout=0., emb_dropout=0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width),
nn.Linear(patch_dim, dim)
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # nn.Parameter()定义可学习参数
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img) # b c (h p1) (w p2) -> b (h w) (p1 p2 c) -> b (h w) dim
b, n, _ = x.shape # b表示batchSize, n表示每个块的个数, _表示一个块内有多少个值
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b) # self.cls_token: (1, 1, dim) -> cls_tokens: (
# batchSize, 1, dim)
x = torch.cat((cls_tokens, x), dim=1) # 将cls_token拼接到patch token中去 (b, 65, dim)
x += self.pos_embedding[:, :(n + 1)] # 加位置嵌入(直接加) (b, 65, dim)
x = self.dropout(x)
x = self.transformer(x) # (b, 65, dim)
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0] # (b, dim)
x = self.to_latent(x) # Identity (b, dim)
# print(x.shape)
return self.mlp_head(x) # (b, num_classes)1.1.3.2、实例化ViT模型进行测试
python
model_vit = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(16, 3, 256, 256)
preds = model_vit(img)
print(preds.shape) # (16, 1000)参考连接:
1.2、使用已有的库
首先需要安装库:pip install vit-pytorch
然后可以发现vit-pytorch中有很多函数,这里举个例子:
python
import torch
from vit_pytorch import SimpleViT
v = SimpleViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)2 Swin Transformer
参考文档:【深度学习】详解 Swin Transformer (SwinT)-CSDN博客
2.1 网络结构
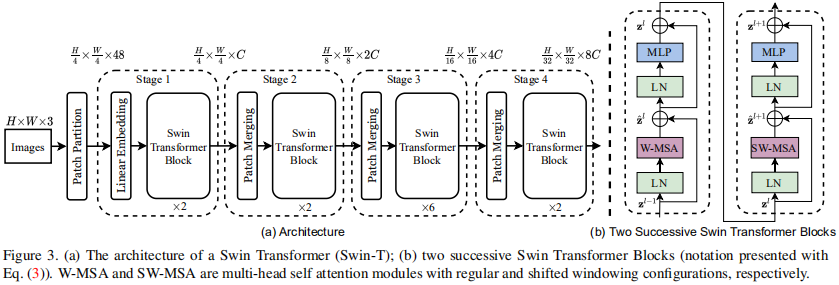
2.1.1 Patch Embedding
将图片输入 Swin Transformer Block 前,需将图片划分成若干 patch tokens 并投影为嵌入向量。更具体地,将输入原始图片划分成一个个 patch_size * patch_size 大小的 patch token,然后投影嵌入。可通过将 2D 卷积层的 stride 和 kernel_size 的大小设为 patch_size,并将输出通道数设为 embed_dim 来实现投影嵌入。最后,展平并置换维度。
python
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) # 输入嵌入投影
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
'''
# 以默认参数为例 # 输入 (B, C, H, W) = (B, 3, 224, 224)
x = self.proj(x) # 输出 (B, 96, 224/4, 224/4) = (B, 96, 56, 56)
x = torch.flatten(x, 2) # H W 维展平, 输出 (B, 96, 56*56)
x = torch.transpose(x, 1, 2) # C 维放最后, 输出 (B, 56*56, 96)
'''
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # shape = (B, P_h*P_w, C)
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops2.1.2 Patch Merge
在每个 Stage 前下采样缩小分辨率并减半通道数,从而形成层次化设计并降低运算量 (类似 Pixel Shuffle)
python
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
# reshape
x = x.view(B, H, W, C)
# 在行、列方向以 stride = 2 等间隔抽样, 实现分辨率 1/2 下采样
x0 = x[:, 0::2, 0::2, :] # shape = (B, H/2, W/2, C)
x1 = x[:, 1::2, 0::2, :] # shape = (B, H/2, W/2, C)
x2 = x[:, 0::2, 1::2, :] # shape = (B, H/2, W/2, C)
x3 = x[:, 1::2, 1::2, :] # shape = (B, H/2, W/2, C)
# 拼接 使通道数加倍
x = torch.cat([x0, x1, x2, x3], -1) # shape = (B, H/2, W/2, 4*C)
x = x.view(B, -1, 4 * C) # shape = (B, H*W/4, 4*C)
# FC 使通道数减半
x = self.norm(x)
x = self.reduction(x) # shape = (B, H*W/4, 2*C)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops2.1.3 Window Partition
将shape为(B, H, W, C)的输入张量reshape为shape=($$B*\frac{H}{W}\frac{H}{W},M, M, C$$)的窗口张量,其中M即为窗口大小。由此,得到$$N=B\frac{H}{W}*\frac{H}{W}$$个
python
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows2.1.4 Window Reverse
即窗口划分的逆过程,将shape=($$B*\frac{H}{W}*\frac{H}{W},M, M, C$$)的窗口张量reshape回
python
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x2.1.5 MLP
使用 GELU 激活函数 + Dropout 的两层 FCs。
python
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x2.1.6 Window Attension (W-MSA Module)
局部窗口内的自注意力,将图片划分为多个窗口之后,计算窗口内的自注意力。计算时引入了相对自注意力。
python
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # 通常默认 wh = ww = w = 4
self.num_heads = num_heads # MHA 的头数
head_dim = dim // num_heads # dim 平均分给每个 head
self.scale = qk_scale or head_dim ** -0.5 # MHA 内的 scale 分母: 自定义的 qk_scale 或 根号 d
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # (2*wh-1 * 2*ww-1, num_heads)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0]) # wh
coords_w = torch.arange(self.window_size[1]) # ww
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # (2, wh, ww)
coords_flatten = torch.flatten(coords, 1) # (2, wh*ww)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # (2, wh*ww, wh*ww)
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # (wh*ww, wh*ww, 2)
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # (wh*ww, wh*ww)
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# 默认 N = wh*ww = w*w = 16
# 默认 num_windows = (H*W)//(wh*ww) = (H*W)//16
# 默认 C = 3
# (num_windows*B, N, C) = (num_windows*B, wh*ww, C)
B_, N, C = x.shape
# (num_windows*B, N, C, num_heads, C//num_heads) -> (C, num_windows*B, num_heads, wh*ww, C//num_heads)
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# (num_windows*B, num_heads, wh*ww, C//num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# (num_windows*B, num_heads, wh*ww, C//num_heads)
q = q * self.scale
# (num_windows*B, num_heads, wh*ww, C//num_heads) * (num_windows*B, num_heads, C//num_heads, wh*ww) = (num_windows*B, num_heads, wh*ww, wh*ww)
attn = (q @ k.transpose(-2, -1))
# (wh*ww, wh*ww, num_heads)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
# (num_heads, wh*ww, wh*ww)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
# (num_heads, wh*ww, wh*ww) -> (1, num_heads, wh*ww, wh*ww) -> (num_windows*B, num_heads, wh*ww, wh*ww)
attn = attn + relative_position_bias.unsqueeze(0) #
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
# (num_windows*B, num_heads, wh*ww, wh*ww)
attn = self.attn_drop(attn)
# (num_windows*B, num_heads, wh*ww, wh*ww) * (num_windows*B, num_heads, wh*ww, C//num_heads) = (num_windows*B, num_heads, wh*ww, C//num_heads)
# (num_windows*B, num_heads, wh*ww, C//num_heads) -> (num_windows*B, wh*ww, num_heads, C//num_heads) -> (num_windows*B, wh*ww, C) = (N*B, wh*ww, C)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops2.1.7 Swin Transformer Block
python
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
##################### 循环移位局部窗口自注意力 #####################
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops2.1.8 Basic Layer
Basic Layer 即 Swin Transformer 的各 Stage,包含了若干 Swin Transformer Blocks 及 其他层。
注意,一个 Stage 包含的 Swin Transformer Blocks 的个数必须是 偶数,因为需交替包含一个含有 Window Attention (W-MSA) 的 Layer 和含有 Shifted Window Attention (SW-MSA) 的 Layer。
python
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops2.2 综合
2.2.1 完整的类定义
python
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops2.2.2 实例化进行测试
python
Net = SwinTransformer(img_size=224, in_chans=3, num_classes=10)
img = torch.randn(16, 3, 224, 224)
preds = Net(img)
print(preds.shape) # torch.Size([16, 10])